AIE Auto Vectorize Tool¶
Auto-Vectorizer: Compilation flow¶
VSI Auto-Vectorizer generates AI kernel from C/C++ source code and all necessary host code. After generating AI Kernel and Xilinx AIE compiler compiles the host code and generates the executables to run in AI Engine. In the compilation flow, VSI auto-vectorizer sits in front of the AIE Compiler. Following figure shows the compilation flow:
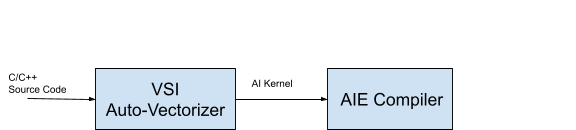
AIE Demo in VSI¶
Following steps shows creating versal platform ,versal system and AIE Vectorized code.
- Start the VSI tool:
- Open a Command Terminal and type: vsi
- Under “Quick Start”:
- select “Open Example Project”
- Under “Create an Example Project”, select Next
- Under “Select Project Template”, Select Next.
- Under the “Project Name” set the name and location for the example project:
- Set the “Project name” to “aie_demo”
- Set the “Project location” to “/project/path/”
- If not already selected, check “Create project subdirectory”
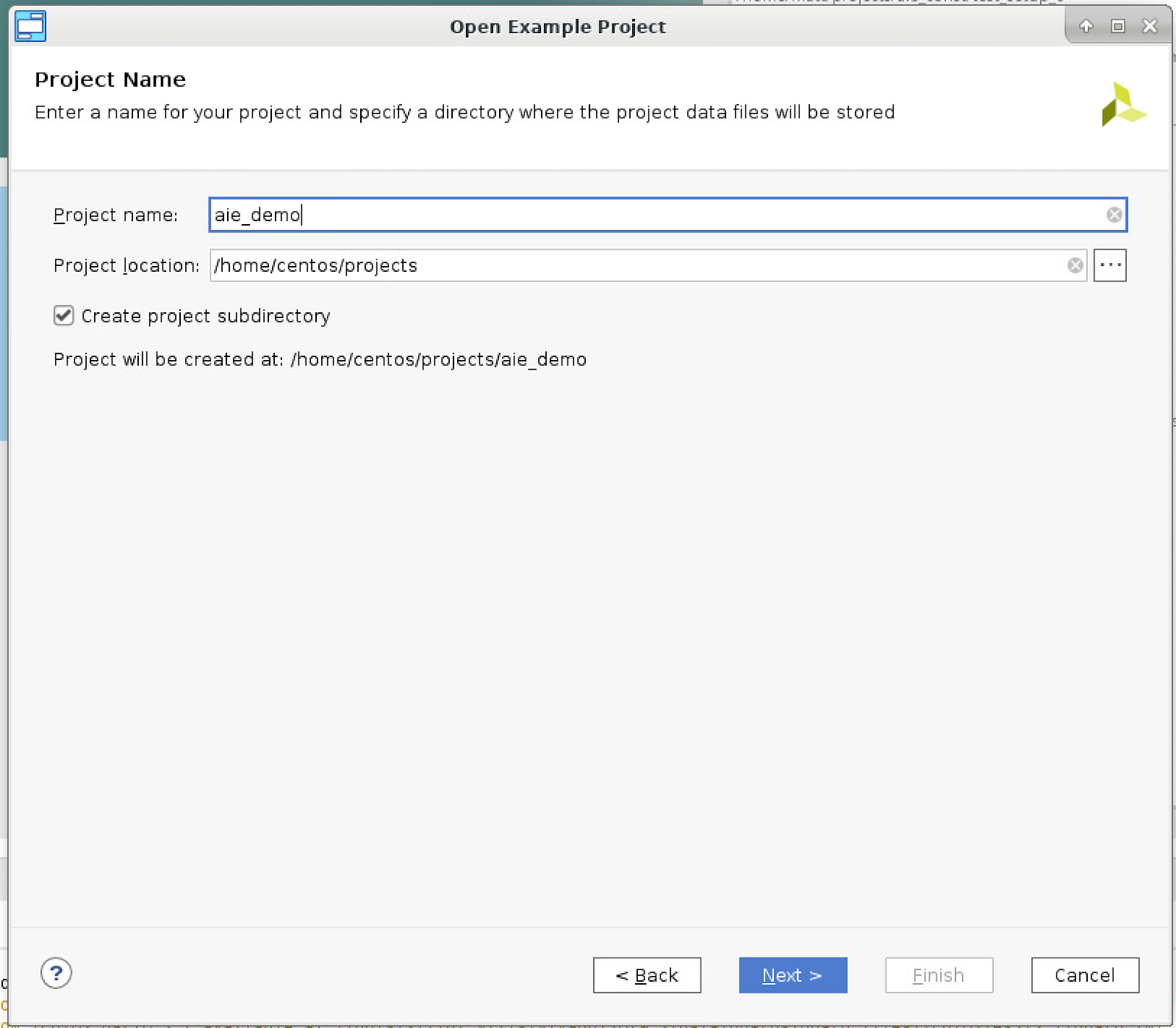
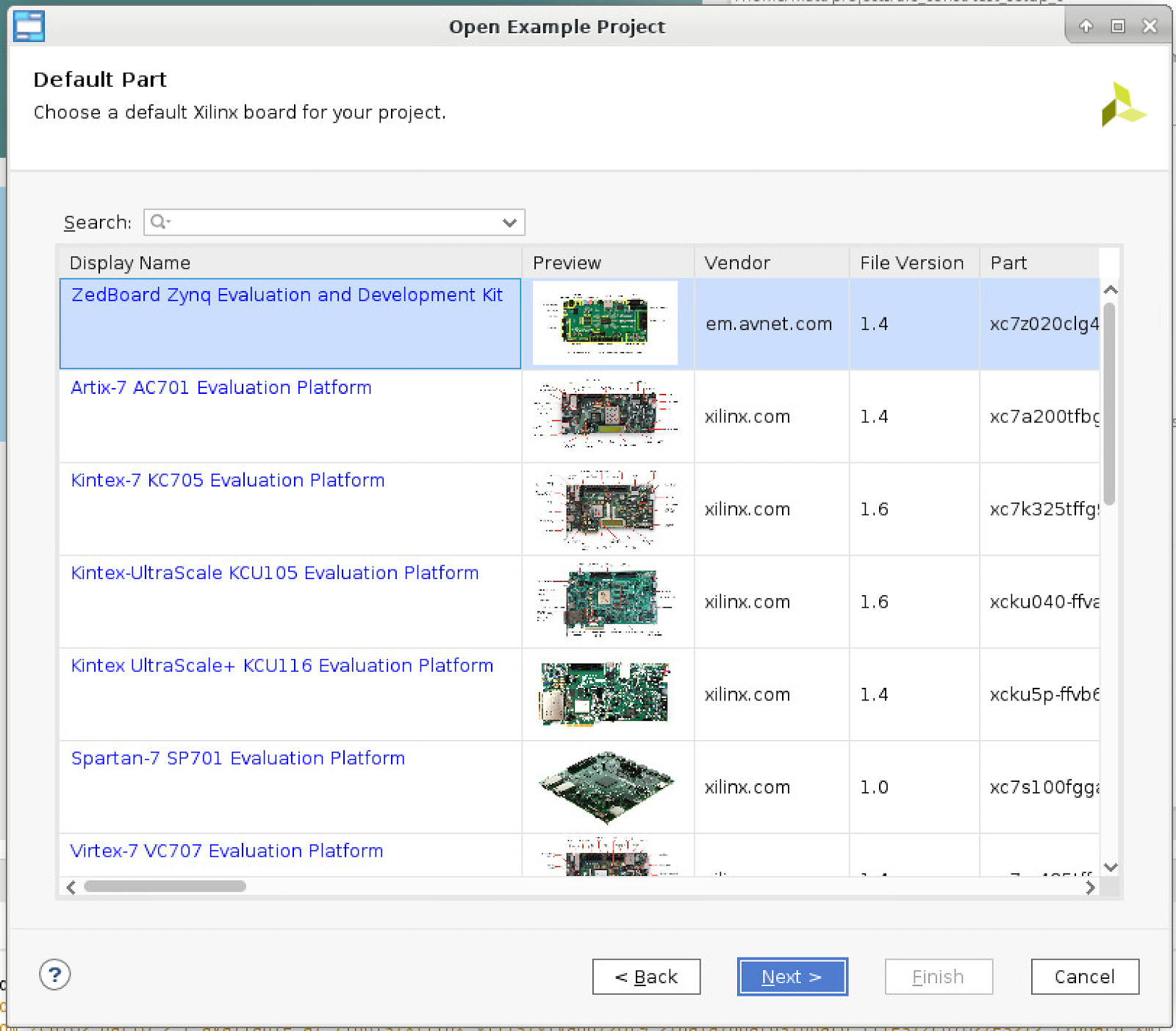
- Under the “Default Part” window, select Next.
-In this example, the part is automatically set in the platform, so selecting the part is not necessary.
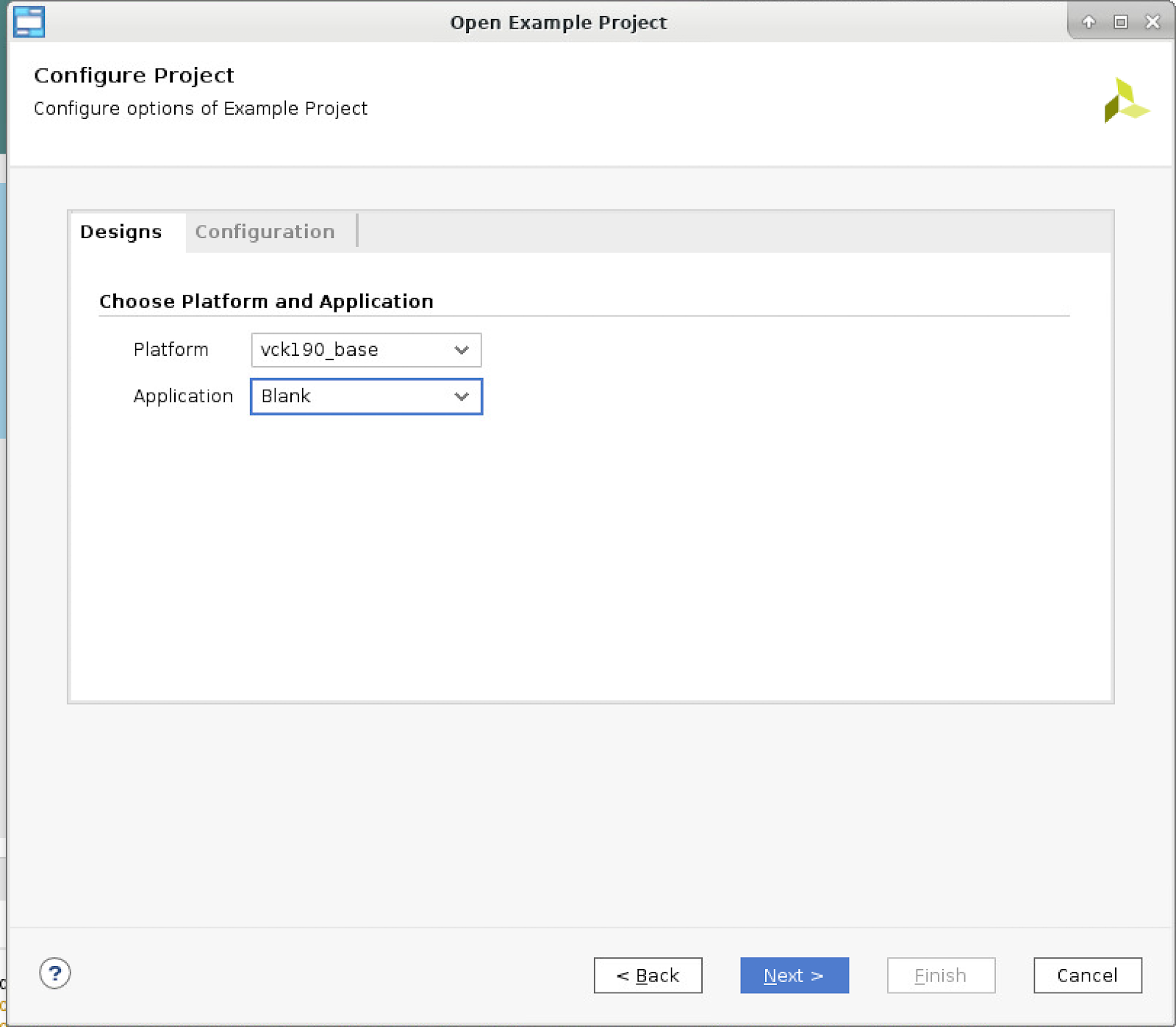
- Under “Configure Project” select a platform and application:
- Set the platform to “vck190_base”
- Leave the Application blank. The application will be built at a later time.
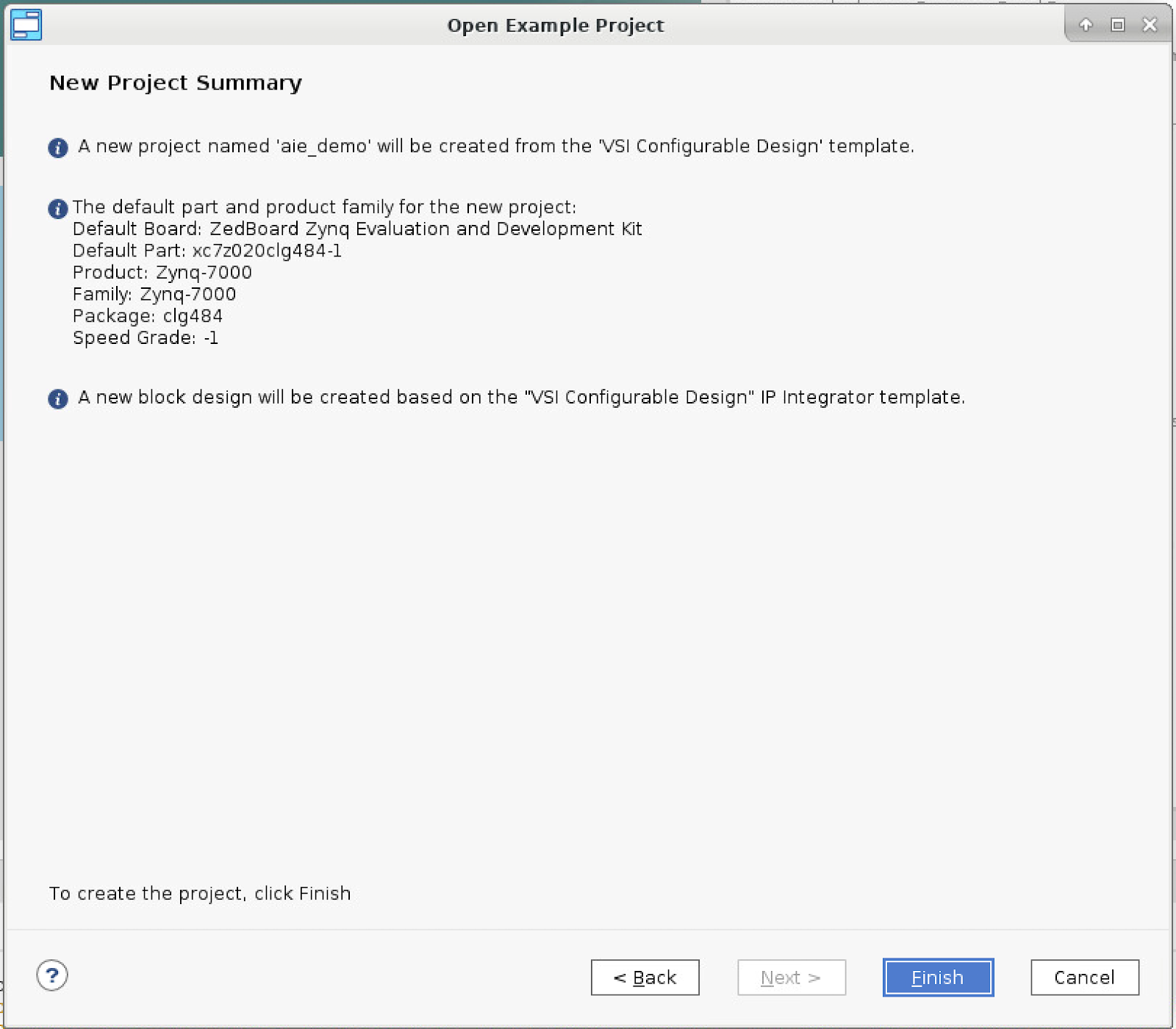
- Under “New Project Summary”, select Finish
- select “Open Example Project”
- Open the Platform:
- From the menu bar select: Flow -> Open Platform -> vck190_base_platform.bd
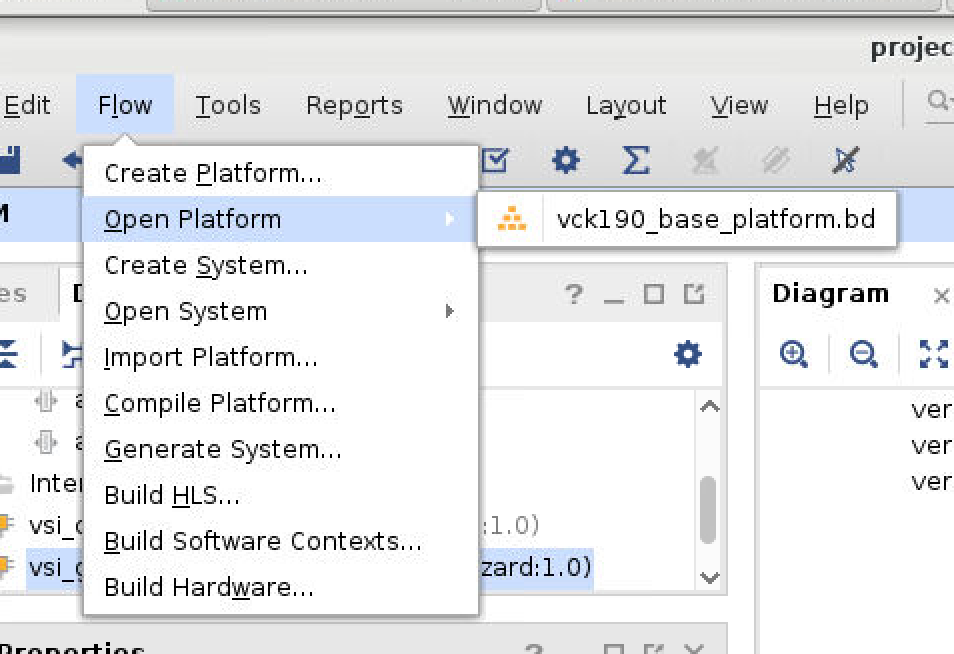
- From the menu bar select: Flow -> Open Platform -> vck190_base_platform.bd
- Compile the Platform:
- From the menu bar select: Flow -> Compile Platform -> Select Ok
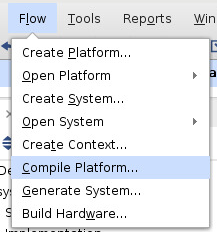
- From the menu bar select: Flow -> Compile Platform -> Select Ok
- Create the System:
- From the menu bar select: Flow -> Create System
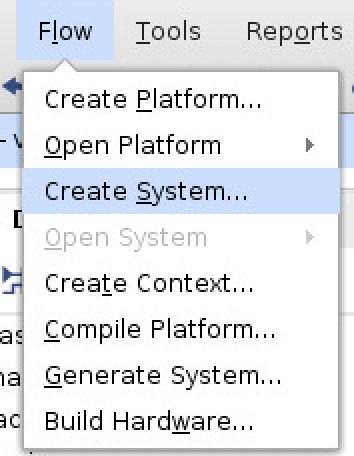
- From the menu bar select: Flow -> Create System
- Import the platform created:
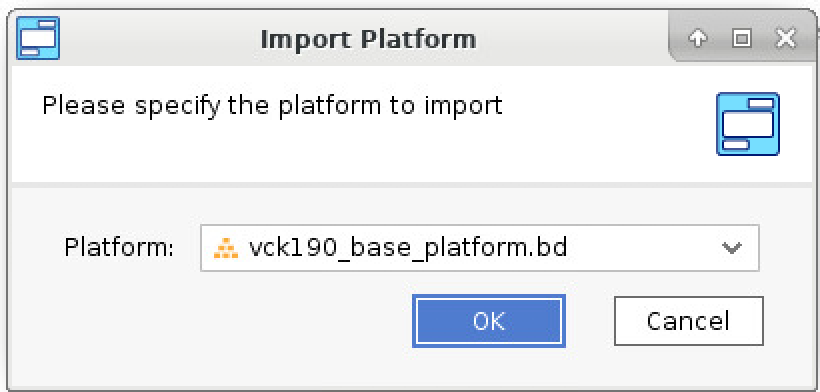
- From the menu bar select: Flow -> Import Platform -> Set the “Platform” as “vck190_base_platform.bd” -> Select Ok
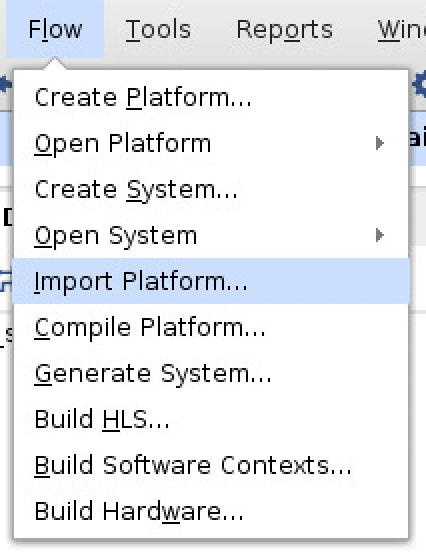
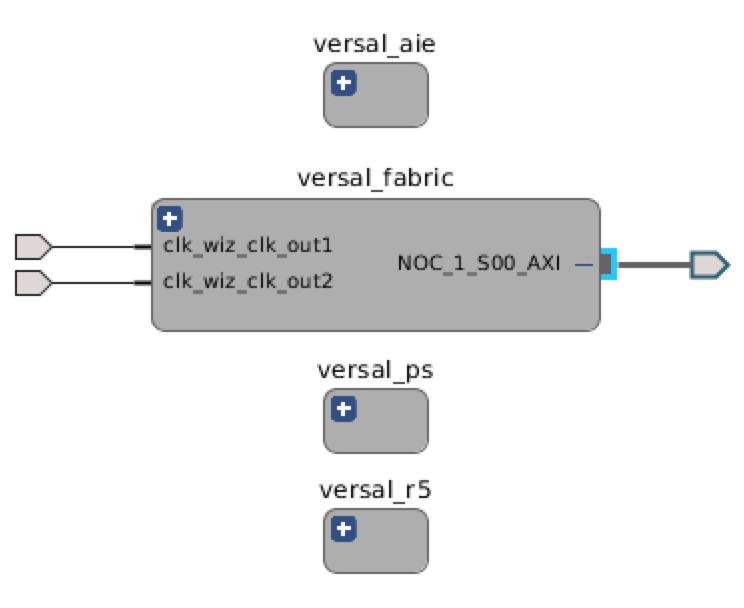
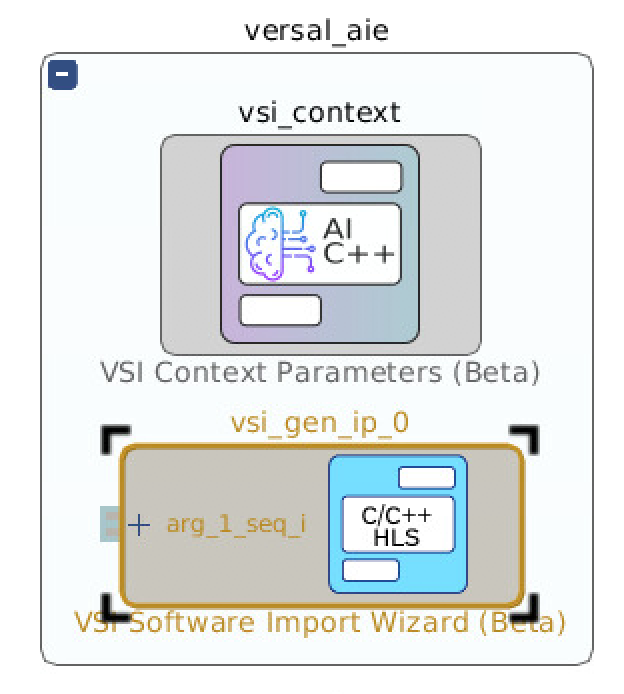
- Click the “+” symbol on the top left of versal_aie block to show what is inside
- From the menu bar select: Flow -> Import Platform -> Set the “Platform” as “vck190_base_platform.bd” -> Select Ok
- We will now start building our system, first we will import some of our code into the AI engines
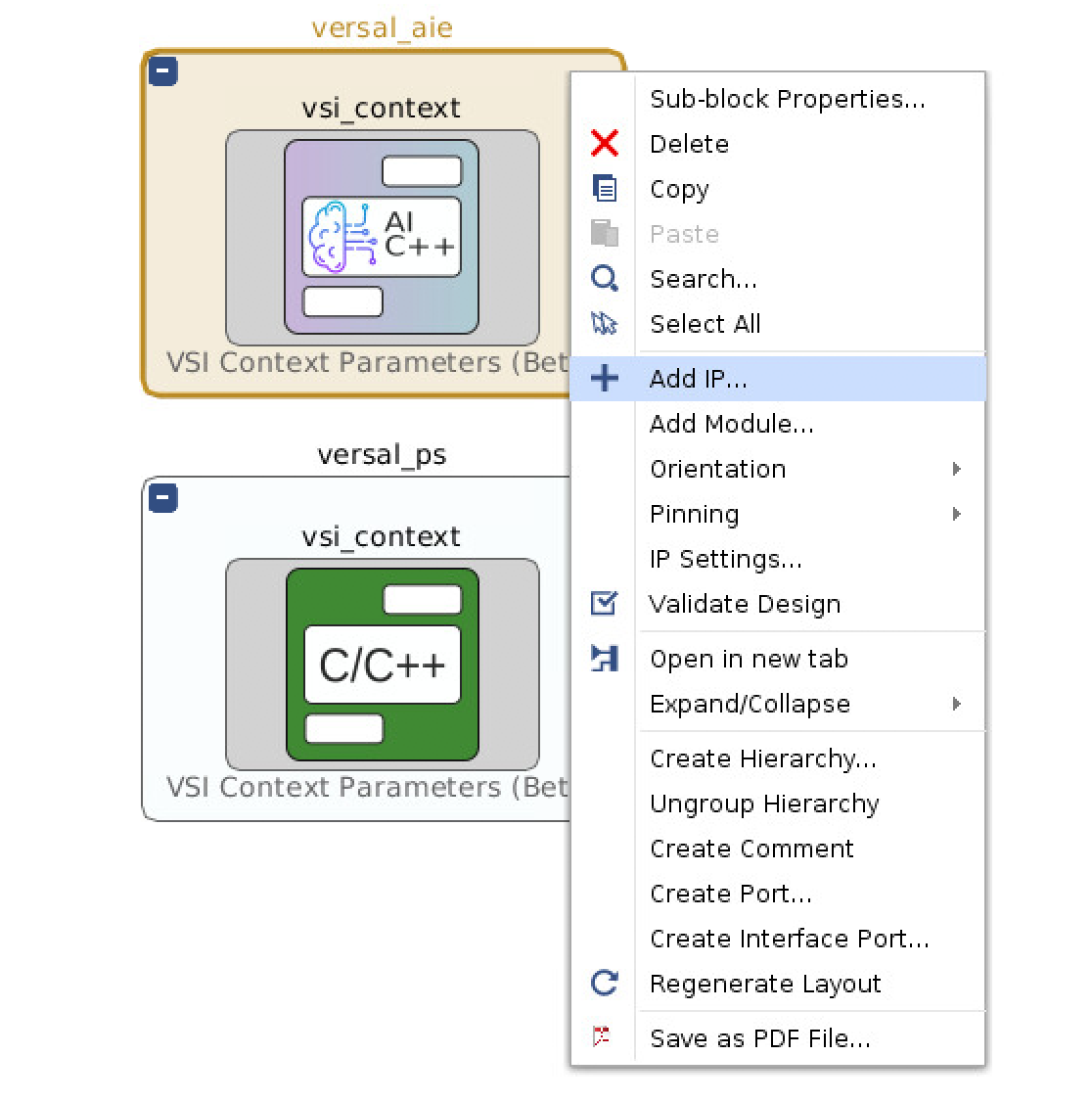
- Click on the “versal_aie” hierarchy context
- Within the “versal_aie” hierarchy context right-click and select “Add IP…”
- Select “VSI Software Import Wizard”
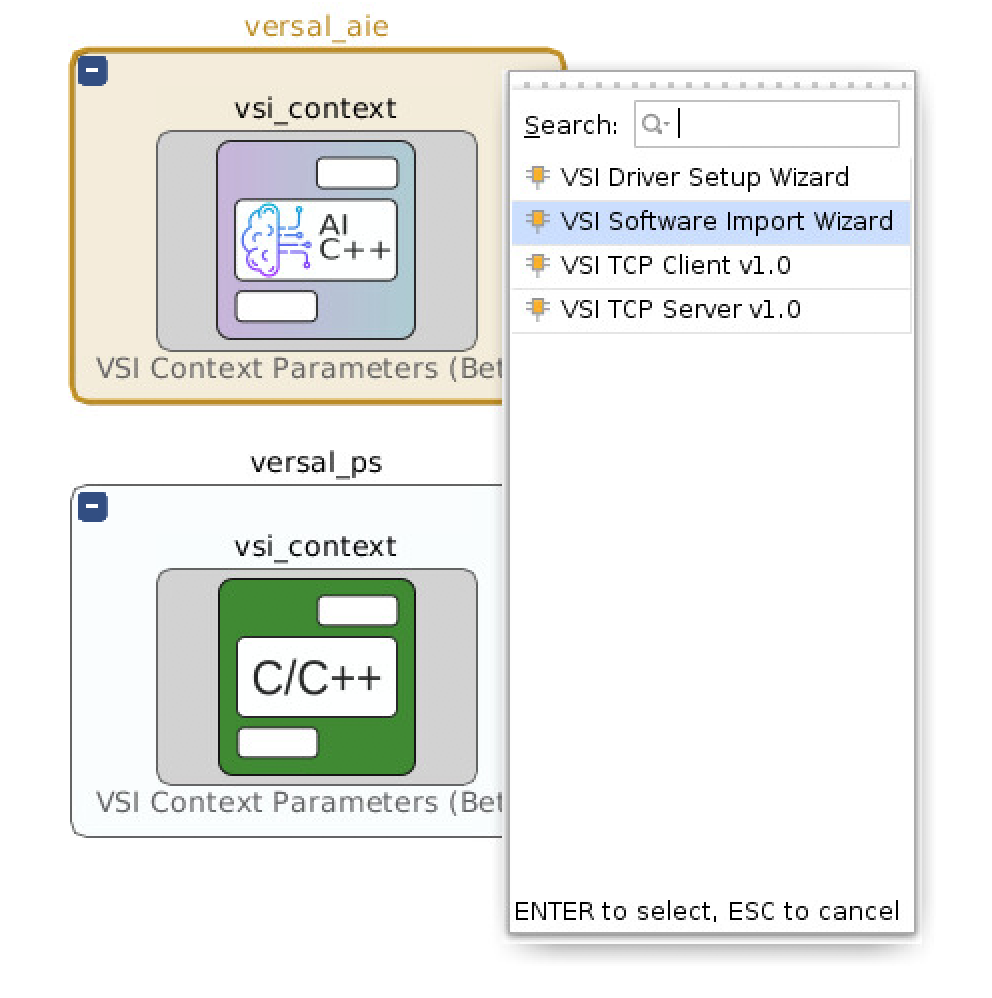
- Double click on the created block to configure the software import wizard
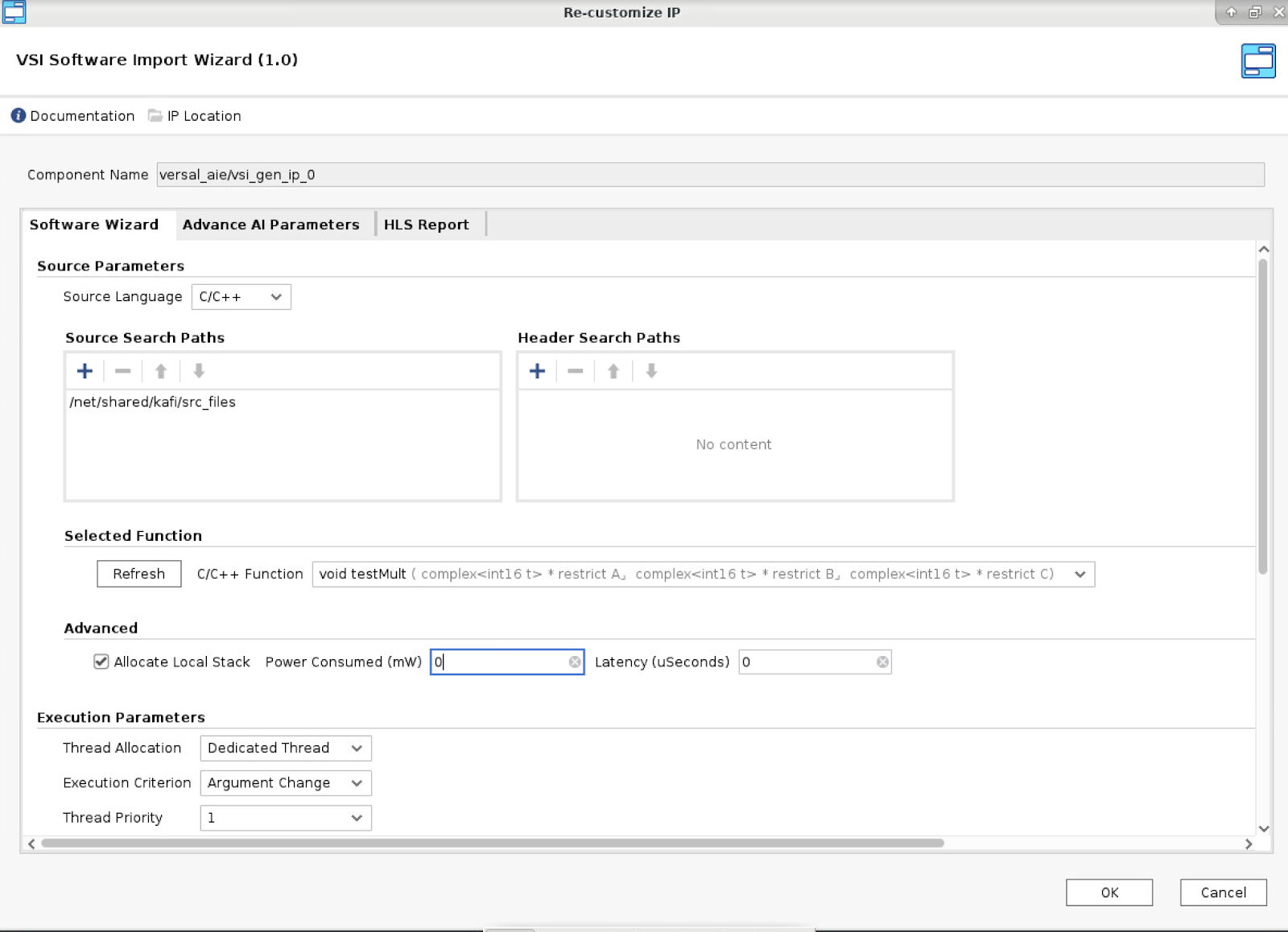
- The import software wizard is a powerful IP that allows users to import their software from any source file into the system. Within the “Software Import Wizard”:
- Under Source Search Paths, click “+” to set the “Source Directory”
- Set C/C++ Function that needs to vectorize.
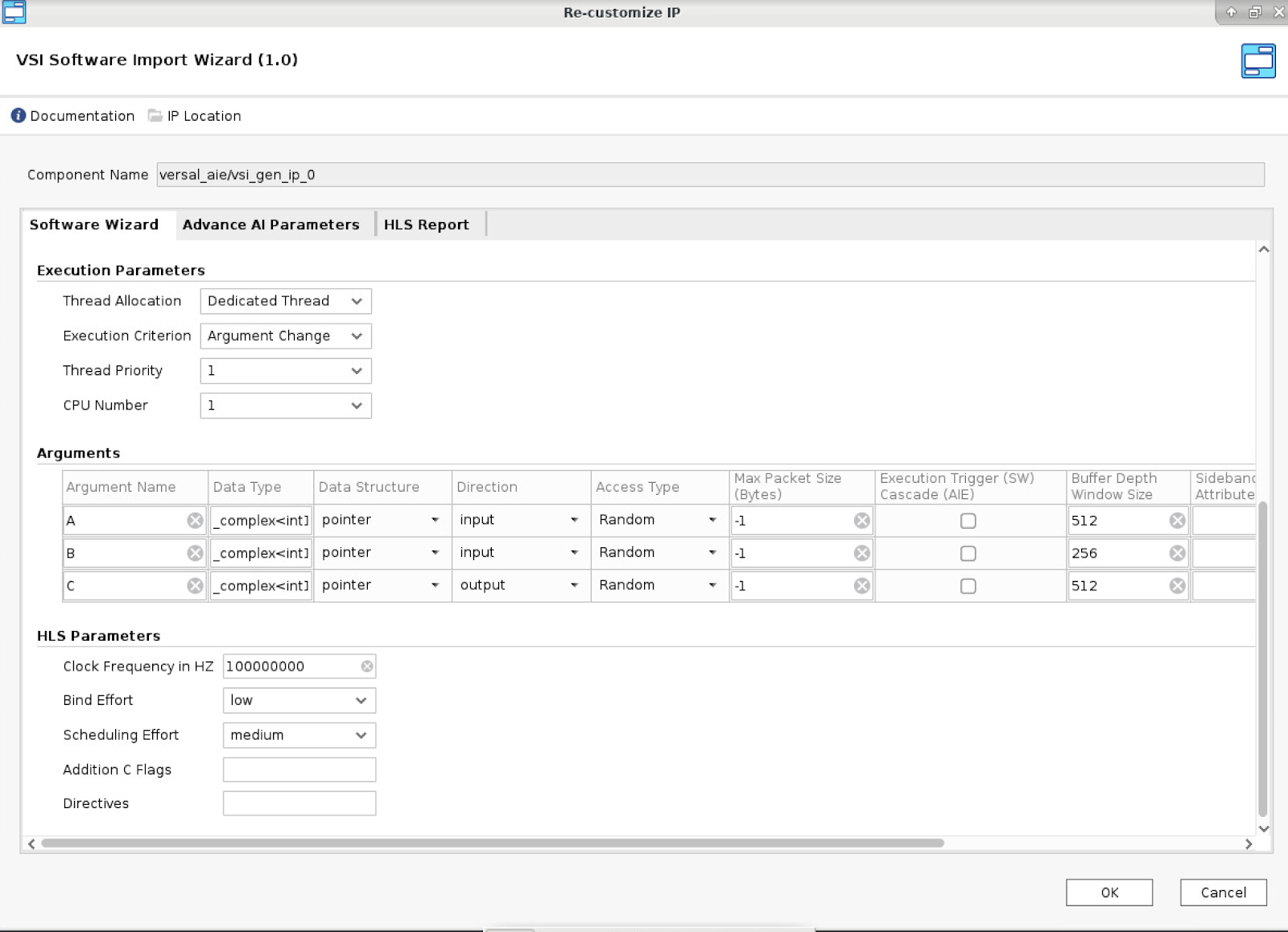
- Set the direction of input/output
- Set access type: random for window type and sequential for stream type
- For window type set Buffer depth window size
- Click the Advance AI parameter tab and select the AIE Auto-Vectorized Compiler option Full Vectorization
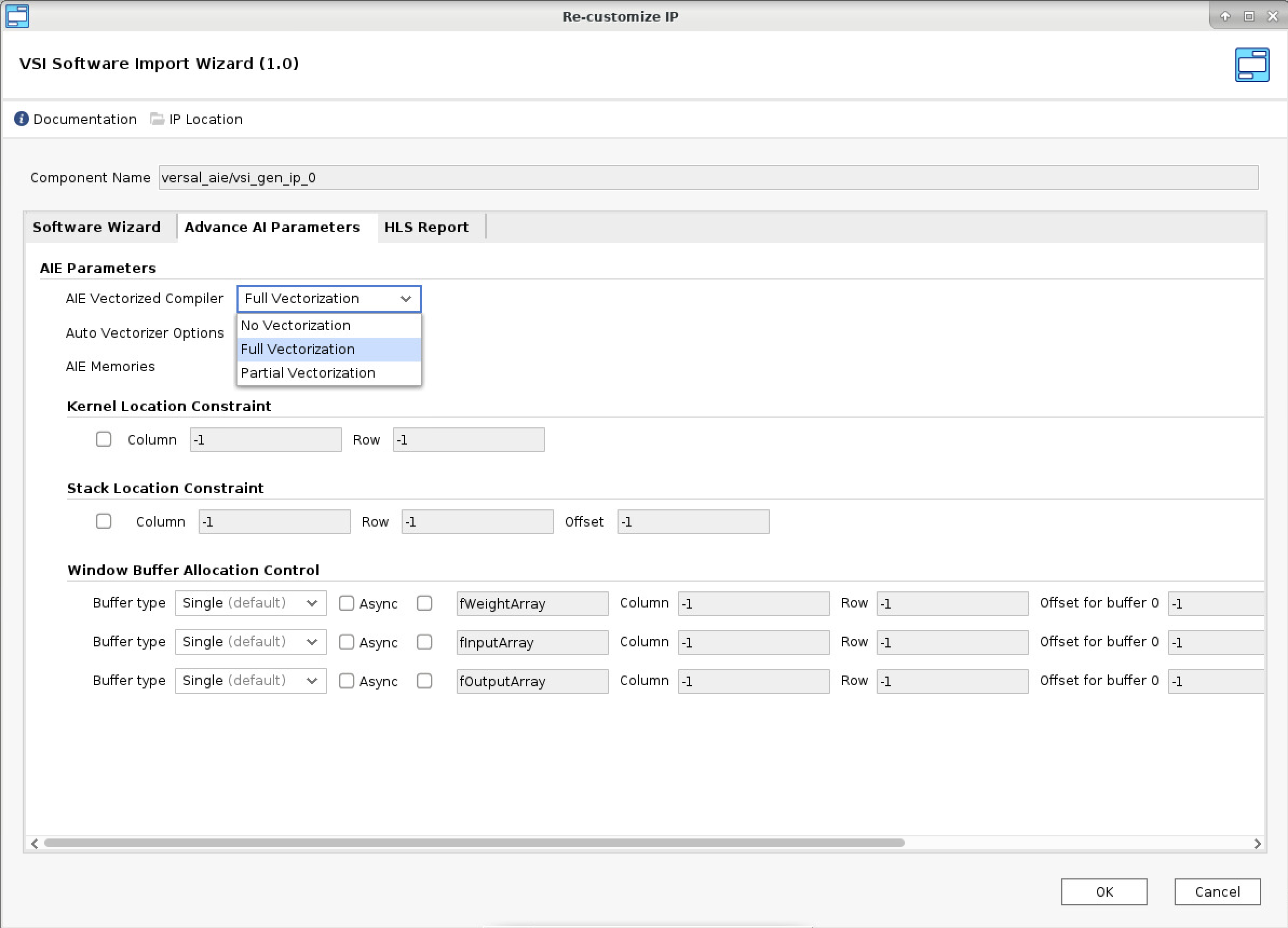
- Select “OK”
- From the menu bar select: Flow -> Generate System -> Select OK
- Generate System will generate the AIE vectorized code for the project.
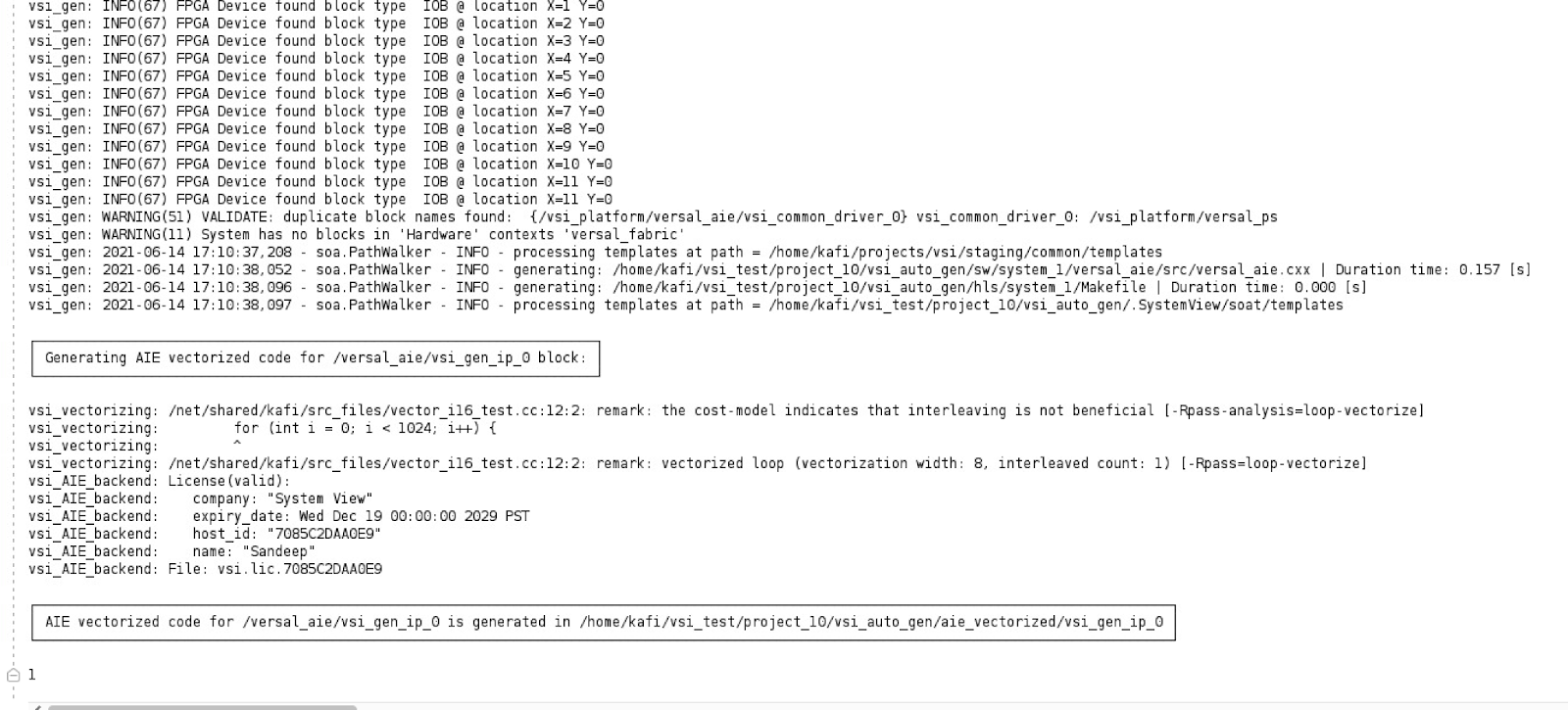
- Generate System will generate the AIE vectorized code for the project.
Auto-Vectorizer: Source code Modifications¶
Source code top function return type and input/output arguments¶
The auto-vectorizer C/C++ source code top function should be void type and inputs/outputs are pointer type. In order to generate optimized code, users should use restrict keyword in inputs/outputs pointer type declaration.
Original code-
float * vectorTest(float * A, float * B) {
float * tmp = new float[64]
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++) {
tmp[i] = A[i] * B[i];
}
return tmp;
}
Modified code-
void vector_test(float * __restrict__ A, float * __restrict__ B, float * __restrict__ C) {
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++) {
C[i] = A[i] * B[i];
}
}
Conditional statement vectorization¶
In order to vectorize the conditional statement and help auto-vectorizer generate optimized code. User need to do following modifications:
Original code-
void vector_i16_test(int32_t * __restrict__ A, int32_t * __restrict__ B, int32_t * __restrict__ C) {
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++) {
if(A[i] > 32)
C[i] = B[i] * 4;
else
C[i] = 0;
}
}
Modified code-
void vector_i16_test(int32_t * __restrict__ A, int32_t * __restrict__ B, int32_t * __restrict__ C) {
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++) {
C[i] = B[i] * 4;
if(A[i] < 32)
C[i] = 0;
}
}
Inner loop function vectorization¶
In auto-vectorizer C/C++ source code, if the inner loop has a function call, in order to vectorize the inner loop, the function should be static inlinable:
Original code-
float sampleFunc( float input_val) {
if(input > 16)
return sinf(input_val)*2.0f;
else
return cosf(input_val)+6.0f;
}
void vector_test(float * __restrict__ A, float * __restrict__ B, float * __restrict__ C) {
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++) {
C[i] = A[i] * sampleFunc(B[i]);
}
}
Modified code-
static inline float sampleFunc( float input_val) {
if(input > 16)
return sinf(input_val)*2.0f;
else
return cosf(input_val)+6.0f;
}
void vector_test(float * __restrict__ A, float * __restrict__ B, float * __restrict__ C) {
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++) {
C[i] = A[i] * sampleFunc(B[i]);
}
}
Auto-Vectorizer: Features¶
VSI Complex Operations¶
Auto vectorizer supports complex arithmetic operations and generates vector complex intrinsic functions/API in AIE Engine kernel. To use the complex type feature, users need to include the “_complex.h” header file in the C/C++ source code.
#include “_complex.h”
Auto-Vectorizer supports following complex arithmetic operations for float, int32 and int16 types. Complex Addition. Complex Subtraction. Complex Multiplication. Complex Multiplication with int/float. Complex Multiply-Accumulate. Complex Multiply-Subtraction. Complex Conjugate. Complex Normalization. Complex Reduction
Code example: Float type
#include "_complex.h"
void complex_float(_complex<float> * __restrict__ A,
_complex<float> * __restrict__ B,
_complex<float> * __restrict__ C) {
_complex<float> complex_var(2.0f, 2.5f);
float float_var = 5.5f;
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++)
C[i] = A[i] + B[i]; // complex float addition
// C[i] = A[i] - B[i]; // complex float subtraction
// C[i] = A[i] * B[i]; // complex float multiplication
// C[i] = A[i] * float_var; // complex float multiply with float
// C[i] = A[i] + B[i] * complex_var; // complex float multiply-accumulate
// C[i] = A[i] - B[i] * complex_var; // complex float multiply-subtraction
// C[i] = A[i] + B[i] * float_var; // complex mult-accumulate with float
// C[i] = A[i] - B[i] * float_var; // complex mult-subtraction with float
// C[i] = cconj(A[i]+B[i]); // complex conjugate
// C[i] = cnorm(A[i]+B[i]); // complex normalization
// C[0] += (A[i] + B[i]); // complex reduction
// C[0] -= (A[i] + B[i]); // complex reduction
}
Code example: int32_t type
void complex_int32(_complex<int32_t> * __restrict__ A, _complex<int32_t> * __restrict__ B, _complex<int32_t> * __restrict__ C) {
_complex<int32_t> complex_var(2, 3);
int32_t int32_var = 5;
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++)
C[i] = A[i] + B[i]; // complex int32_t addition
// C[i] = A[i] - B[i]; // complex int32_t subtraction
// C[i] = A[i] * B[i]; // complex int32_t multiplication
// C[i] = A[i] * int32_var; // complex int32 multiply with int32
// C[i] = A[i] + B[i] * complex_var; // complex int32_t multiply-accumulate
// C[i] = A[i] - B[i] * complex_var; // complex int32_t multiply-subtraction
// C[i] = A[i] + B[i] * int32_var; // complex mult-accumulate with int32
// C[i] = A[i] - B[i] * int32_var; // complex mult-subtraction with int32
// C[i] = cconj(A[i]+B[i]); // complex conjugate
// C[i] = cnorm(A[i]+B[i]); // complex normalization
// C[0] += (A[i] + B[i]); // complex reduction
// C[0] -= (A[i] + B[i]); // complex reduction
}
Code example: int16_t type
void complex_int16(_complex<int16_t> * __restrict__ A, _complex<int16_t> * __restrict__ B, _complex<int16_t> * __restrict__ C) {
_complex<int16_t> complex_var(2, 3);
int16_t int16_var = 5;
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++)
C[i] = A[i] + B[i]; // complex int16_t addition
// C[i] = A[i] - B[i]; // complex int16_t subtraction
// C[i] = A[i] * B[i]; // complex int16_t multiplication
// C[i] = A[i] * int16_var; // complex int16_t multiply with float
// C[i] = A[i] + B[i] * complex_var; // complex int16_t multiply-accumulate
// C[i] = A[i] - B[i] * complex_var; // complex int16_t multiply-subtraction
// C[i] = A[i] + B[i] * int16_var; // complex mult-accumulate with int16_t
// C[i] = A[i] - B[i] * int16_var; // complex mult-subtraction with int16_t
// C[i] = cconj(A[i]+B[i]); // complex conjugate
// C[i] = cnorm(A[i]+B[i]); // complex normalization
// C[0] += (A[i] + B[i]); // complex reduction
// C[0] -= (A[i] + B[i]); // complex reduction
}
Stream support¶
VSI Auto-vectorizer supports stream arguments for int16, int32, float, cint16, cint32 and cfloat type. In C/C++ source code, users can use top function complex arguments and using VSI auto-vectorizer, users can generate AIE kernels with input/output stream types. Following examples of shows the generated AIE kernel with stream arguments from C/C++ source code:
Example-1: Source Code:
#include “_complex.h”
void stream_test(_complex<int32_t> * __restrict__ A,
_complex<float> * __restrict__ B,
_complex<int32_t> * __restrict__ C0,
_complex<float> * __restrict__ C1) {
_complex<int32_t> three(3,3);
_complex<float> two(2.0f,2.0f);
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++)
C0[i] = A[i] + three;
#pragma clang loop vectorize(enable)
for (int i = 0 ; i < 64; i++)
C1[i] = B[i] + two;
}
Generated AIE Kernel Code:
void __stream_test(input_stream_cint32 * restrict A,
input_stream_cfloat * restrict B,
output_stream_cint32 * restrict C0,
output_stream_cfloat * restrict C1) {
int64_t call_i;
v16int32 broadcast_splat58;
int64_t index;
int64_t index__PHI_TEMPORARY;
int64_t index_next;
double call_i44;
v16float broadcast_splat72;
int64_t index63;
int64_t index63__PHI_TEMPORARY;
int64_t index_next64;
call_i = /*tail*/ vsi_cconstructor(3, 3);
broadcast_splat58 = as_v16int32(aie::broadcast<cint32,8>(aie::vector<cint32,8>(as_v8cint32(vsi_complex_upd_elem(null_v16int32(),0u,call_i))).get(0)));
index__PHI_TEMPORARY = 0;
for (;;) /* Syntactic loop 'vector.body prevent chess from unrolling */
chess_unroll_loop(1) chess_loop_count(8) chess_require_pipelining(1)
{
vector_body:
index = index__PHI_TEMPORARY;
v16int32 wide_load = as_v16int32(concat(readincr_v2(A),readincr_v2(A),readincr_v2(A),readincr_v2(A)));
v16int32 tmp__1 = as_v16int32(aie::add(aie::vector<cint32, 8>(as_v8cint32(wide_load)),aie::vector<cint32, 8>(as_v8cint32(broadcast_splat58))));
v16int32 stream_store_tmp_0 = tmp__1;
writeincr_v2(C0, as_v2cint32(ext_v(stream_store_tmp_0, 0)));
writeincr_v2(C0, as_v2cint32(ext_v(stream_store_tmp_0, 1)));
writeincr_v2(C0, as_v2cint32(ext_v(stream_store_tmp_0, 2)));
writeincr_v2(C0, as_v2cint32(ext_v(stream_store_tmp_0, 3)));
index_next = ((int64_t)(((int64_t)index) + ((int64_t)8)));
if (chess_copy(index_next) == 64) {
break;
} else {
index__PHI_TEMPORARY = index_next; /* for PHI node */
continue;
}
} /* end of syntactic loop 'vector.body' */
vector_ph62:
call_i44 = /*tail*/ vsi_cfconstructor(2.000000e+00, 2.000000e+00);
broadcast_splat72 = as_v16float(aie::broadcast<cfloat,8>(aie::vector<cfloat,8>(as_v8cfloat(vsi_complex_upd_elem(null_v16float(),0u,call_i44))).get(0)));
index63__PHI_TEMPORARY = 0; /* for PHI node */
for (;;) /* Syntactic loop 'vector.body59 prevent chess from unrolling */
chess_unroll_loop(1) chess_loop_count(8) chess_require_pipelining(1)
{
vector_body59:
index63 = index63__PHI_TEMPORARY;
v16int32 wide_load70 = as_v16int32(concat(readincr_v2((input_stream_cint32 *)B),readincr_v2((input_stream_cint32 *)B),readincr_v2((input_stream_cint32 *)B),readincr_v2((input_stream_cint32 *)B)));
v16float tmp__2 = as_v16float(aie::add(aie::vector<cfloat, 8>(as_v8cfloat(wide_load70)),aie::vector<cfloat, 8>(as_v8cfloat(broadcast_splat72))));
v16float stream_store_tmp_1 = tmp__2;
writeincr_v2((output_stream_cint32 *)C1, as_v2cint32(ext_v(stream_store_tmp_1, 0)));
writeincr_v2((output_stream_cint32 *)C1, as_v2cint32(ext_v(stream_store_tmp_1, 1)));
writeincr_v2((output_stream_cint32 *)C1, as_v2cint32(ext_v(stream_store_tmp_1, 2)));
writeincr_v2((output_stream_cint32 *)C1, as_v2cint32(ext_v(stream_store_tmp_1, 3)));
index_next64 = ((int64_t)(((int64_t)index63) + ((int64_t)8)));
if (chess_copy(index_next64) == 64) {
break;
} else {
index63__PHI_TEMPORARY = index_next64; /* for PHI node */
continue;
}
} /* end of syntactic loop 'vector.body59' */
for_cond_cleanup15:
return;
}
Example-2: Source Code:
static int32_t coeff_0[8] = {1,2,3,4,5,6,7,8};
static float coeff_1[8] = {2.0f,3.0f,4.0f,5.0f,6.0f,7.0f,8.0f,9.0f};
void stream_test(int32_t * __restrict__ A, float * __restrict__ B,
int32_t * __restrict__ C0, float * __restrict__ C1) {
while(1) {
#pragma clang loop vectorize(enable)
for (int i=0 ; i < 8; i++) {
*C0++ = (*A++ * coeff_0[i]);
*C1++ = (*B++ * coeff_1[i]);
}
}
}
Generated AIE Kernel Code:
static int32_t _ZL7coeff_0[8] = { 1, 2, 3, 4, 5, 6, 7, 8 };
static float _ZL7coeff_1[8] = { 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00, 7.000000e+00, 8.000000e+00, 9.000000e+00 };
void __stream_test(input_stream_int32 * restrict A,
input_stream_float * restrict B,
output_stream_int32 * restrict C0,
output_stream_float * restrict C1) {
int64_t index;
int64_t index__PHI_TEMPORARY;
for (;;) /* Syntactic loop 'vector.ph prevent chess from unrolling */
chess_unroll_loop(1)
{
vector_ph:
index__PHI_TEMPORARY = 0; /* for PHI node */
for (;;) /* Syntactic loop 'vector.body prevent chess from unrolling */
chess_unroll_loop(1)
{
vector_body:
index = index__PHI_TEMPORARY;
v8int32 wide_load = concat(readincr_v4(A),readincr_v4(A));
v8int32 wide_load26 = *((v8int32*)(&_ZL7coeff_0[((int64_t)index)]));
v8int32 stream_store_tmp_0 = srs(mul(wide_load26 , wide_load),0);
writeincr_v4(C0, ext_v(stream_store_tmp_0, 0));
writeincr_v4(C0, ext_v(stream_store_tmp_0, 1));
v8float wide_load27 = concat(readincr_v4(B),readincr_v4(B));
v8float wide_load28 = *((v8float*)(&_ZL7coeff_1[((int64_t)index)]));
v8float stream_store_tmp_1 = as_v8float(aie::mul(aie::vector<float,8>(wide_load28),aie::vector<float,8>(wide_load27)));
writeincr_v4(C1, ext_v(stream_store_tmp_1, 0));
writeincr_v4(C1, ext_v(stream_store_tmp_1, 1));
if (chess_copy(index) == 0) {
goto vector_ph;
} else {
index__PHI_TEMPORARY = ((int64_t)(((int64_t)index) + ((int64_t)8))); /* for PHI node */
continue;
}
} /* end of syntactic loop 'vector.body' */
} /* end of syntactic loop 'vector.ph' */
}
VSI Trigonometric Flags¶
VSI Auto-vectorizer generates sine and cosine function in various modes (AIE intrinsic and Baskara). User can use the sine and cosine function modes using command line arguments as follows:
$./clang_cmd_local.sh -Os sin_fast_test sin_fast_test --trigonometricFlag=original
Generated code:
v8float tmp__1 = llvm_sin_v8f32(wide_load);
v8float tmp__1 = llvm_cos_v8f32(wide_load);
Sine Range: Any input radian CoSine Range: Any input radian
$./clang_cmd_local.sh -Os sin_fast_test sin_fast_test --trigonometricFlag=baskaraOriginal
Generated code:
v8float tmp__1 = sinBaskara(wide_load);
v8float tmp__1 = sinBaskara(wide_load);
Sine Range: [0 … PI] CoSine Range: [-PI/2 … PI/2]
$./clang_cmd_local.sh -Os sin_fast_test sin_fast_test --trigonometricFlag=baskaraUndefRange
Generated code:
v8float tmp__1 = sinBaskaraUndefRange(wide_load);
v8float tmp__1 = cosBaskaraUndefRange(wide_load);
Sine Range: Any input radian CoSine Range: Any input radian